Who would have thought there could be bias in AI models that detect potholes? The answer is yes; there can be bias even when we are not using sensitive data and even when humans are not involved. Dr. Susan Kennedy, Assistant Professor of Philosophy at the University of Santa Clara, focuses on bioethics and the ethics of technology. She teaches ethics in AI, among other courses. In her Embedded Vision Summit 2023 session, Bias in Computer Vision – It’s Bigger Than Facial Recognition, she offered the real-world example of a pothole detection application, Street Bump, developed in Boston and launched in 2012.
In this case study, the city of Boston gathered data from residents’ smartphones to help identify potholes throughout the city. What they did not consider is how they were excluding a swath of the population in the data-gathering process: residents who did not have smartphones, a group that included lower-income and elderly residents. The result? The application only identified potholes in affluent neighborhoods. In this instance, the bias was in how the data was gathered.
Paved vs. Unpaved Roads
“Imagine this application is initially tested in the streets of Santa Clara, California, where it shows impressive accuracy in detecting potholes. Given these promising results, the company decides to roll it out to city maintenance crews across the United States to help increase efficiency in their operations,” Dr. Kennedy explained. “After gaining traction in major cities, this application rolls out in smaller cities and towns such as Marshfield, Wisconsin, where my parents live. A few months after implementation, something starts to go wrong. Residents like my parents notice that the potholes on their roads aren’t being fixed. What happened?”
The application in question was trained on images of concrete potholes and tested on paved roads in the Bay Area. So when it comes to potholes on non-paved roads in rural Wisconsin, the model’s accuracy plummets. “As a result, residents living on dirt roads are left feeling neglected and unfairly treated,” Dr. Kennedy continued. “Even in cases where humans are not the direct subjects of an AI system, there can still be a human impact.”
Automotive Applications & AI Bias
Alex Thaman, founding architect at an AI incubation company, added to the conversation during his Embedded Vision Summit 2023 session, Combating Bias in Production Computer Vision Systems. He focused on bias in predictive and generative AI that involves humans. He shared how the wide range of skin tones, body shapes and sizes, and facial features can be challenging to represent completely in training data. In an interview after his session, Thaman offered insight into how bias creeps into AI models for automotive applications.
“Rare or edge cases are always a struggle,” he said. “Imagine pedestrians that are elderly in wheelchairs; cars or roads in unusual configurations; adverse environmental conditions – for example, heavy rain, snow, fog, or near collisions. Typically [developers] have plenty of data, but it is hard to find and sample these rarer events.”
Thaman went on to explain that certain combinations of scenarios and demographics are cause for concern. For example, in DMS use cases, certain ethnicities are not as well represented in first-world countries where systems are designed and deployed. Backup camera use cases are another concern as they need to identify the full range of babies, toddlers, and children who may be on foot, riding a tricycle, sitting in a stroller, or tucked in a car seat.
Thaman also highlighted the challenges of scaling to other locations. “Stoplights, for instance, have a different look in different places, and many times these computer vision systems have not been built to scale outside limited locales, and now the activity becomes figuring out how the model can generalize without needing to collect new data every time a new city is supported.”

Disparities In Crash Testing
While AI is relatively new to automotive, bias in automotive design is not and has been studied. 2013 NHTSA crash data shows that women are 17 percent more likely to be killed in a crash than males. A 2011 University of Virginia study found women are 47 percent more likely than males to be seriously injured in a crash and 71 percent more likely to be moderately injured. That research, led by Dr. Dipan Bose, concluded that to achieve equity in injury reduction, “health policies and vehicle regulations must focus on effective safety designs tailored toward the female population.”
In 2017, NHTSA began designing its first female crash dummy to replace what was previously a scaled-down male crash dummy. In August 2022, NHTSA announced plans to eliminate any existing disparities in crash outcomes for men and women as well as an update to their 2013 crash data, which showed marked improvement in crash outcomes for females in newer model cars.
As to why bias in AI occurs, Thaman offered a handful of ideas:
- Conditions & Requirements: The development team is unaware of the conditions or requirements under which the data was collected.
- Training & Deployment: The development team does not spend enough time analyzing the data before using it to train and deploy models.
- Clear Communication: Teams collecting and procuring data may not be fully informed about the end goals of the product or application.
- Unintentional Bias: The way the data was collected and sampled might unintentionally lean towards a limited subset of the domain.

Asking Important Questions
Dr. Kennedy’s main hope is that developers will ask themselves the necessary questions to “expand the ethical circle to ensure that all stakeholders who may be directly or indirectly affected by the system have been taken into account.” Among these questions are “Who does it work for, or not work for” (facial recognition systems) and “What does it work for, or not work for” (systems where humans are not the focal point).
“Take the example of pothole detection,” Dr. Kennedy continued. “What does it not work for? Dirt roads. Although this may not seem like an issue of fairness or discrimination at first glance, when we dig a little deeper, we find this kind of bias can have an undesirable human impact.”
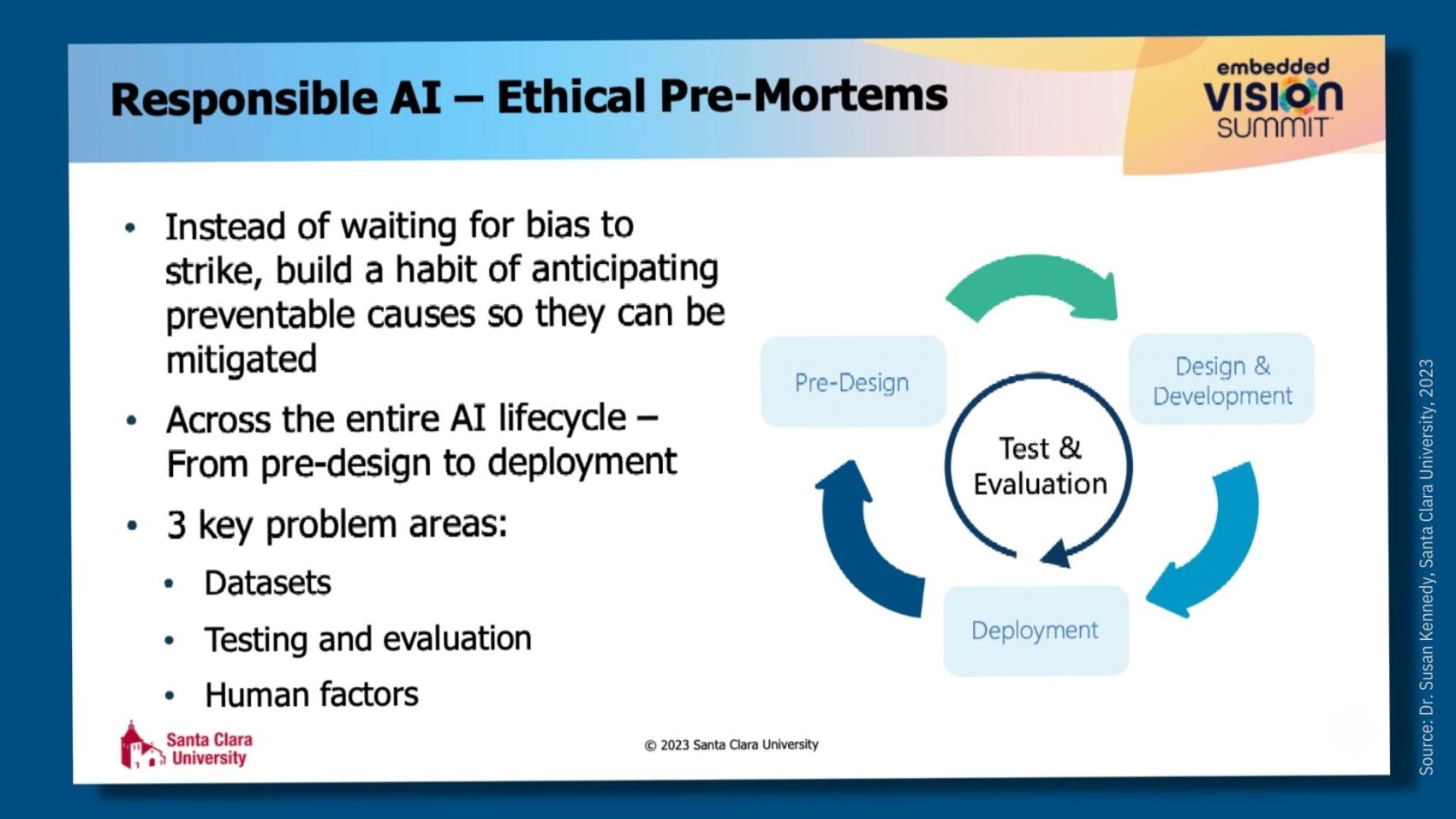
Toolkits like Google’s What-If, IBM’s AI Fairness 360, and Microsoft’s AzureML Responsible AI Dashboard offer developers a good start, making it possible to anticipate what could go wrong in the pre-design phase through to deployment. Alicia Moniz, who attended Dr. Kennedy’s session, is an AI leader at Microsoft. Her book, Beginning Azure Cognitive Services: Data-Driven Decision Making Through Artificial Intelligence, helps developers understand how to integrate machine learning algorithms into their applications. In an interview after Dr. Kennedy’s session, she offered her insight into best practices for mitigating bias in AI.
“Fairness, interpretability, and explainability are fundamental in developing machine learning models responsibly,” Moniz said. “Error analysis and the measurement of bias and fairness in machine learning models help to identify under and overrepresentation in datasets that can help determine if what’s included in a particular training data set is inclusive.”
As described by Moniz, by mapping model performance metrics with metadata identifying data cohorts within the training data set, researchers can gain additional insight (interpretability) as to variance in performance across sensitive and non-sensitive features, such as different genders or income levels. “Explainability, for image-based models, are feature attributions or weights given to each pixel in the input image based on its contribution to the model’s prediction,” Moniz said.
Bias-Free AI vs. Bias-Aware AI
Dr. Kennedy cautioned that while these tools help discover statistical and computational bias – i.e., systematic errors stemming from bias in the datasets and algorithmic processes used – they are only addressing the tip of the iceberg when it comes to bias. She advises developers to keep a sharp lookout for human bias, which is present across the AI lifecycle and in the use of AI once deployed. Dr. Kennedy also encourages developers to be cognizant of systemic bias, which can exist in the datasets used in AI and the institutional norms and practices across the AI lifecycle and in broader society.
She asked us to consider what success might look like when trying to mitigate bias, warning that even if developers do everything in their power to mitigate bias, there will be areas of bias that are not in their power to control. “Bias-free AI is an unachievable goal,” she said.
Dr. Kennedy’s guidance is to take a bias-aware approach, meaning we should consider that AI exists within a more extensive social system and that mitigating it requires a socio-technical approach – i.e., one that recognizes the interrelatedness of an endeavor’s technical, social, and human factor elements. “Instead of waiting for bias to rear its ugly head and then scrambling to fix it, we can develop a habit of anticipating and mitigating preventable causes of bias right from the start,” Dr. Kennedy said.
“From the very start, data should be curated by intentionally collecting from demographic subsets,” Thaman explained. “During the process of development, metrics should be evaluated across these subsets. After releasing to production, AI systems should be monitored for any problems or changes across these populations.”
Synthetic Data: Applications & Use Cases
During his summit session, Thaman suggested developers ensure they are considering demographic information when collecting data to obtain even distributions of men, women, adults, and children. He also recommends collecting more data than needed so developers can experiment with different data quantities across these and other dimensions. He also explored how a dataset can be expanded by using synthetic data to broaden the diversity of a set of images. Synthetic data is often used by data scientists, researchers, and developers to replace or supplement real data in order to improve AI and ML models, safeguard sensitive information, and reduce bias.
We looked at how an image of a single hand could be expanded to include hands in a range of skin tones. Similarly, an image of a face was expanded to include a range of faces representing different ethnicities. While some of the images did not look like the faces of real people, it was interesting to see how technology could be used to expand a dataset to be more inclusive.
As Dr. Kennedy’s insightful session wrapped up, she highlighted what she hoped we would take away from her talk at the 2023 Embedded Vision Summit. “Bias poses ethical challenges, regardless of the stakeholders involved,” she said. “An effective mitigation strategy requires a combination of technical and social considerations.”
What’s essential, she concluded, is to reframe the goal to be bias-aware, not bias-free. It seems no job is too small to include reflections on bias and how we can mitigate it, even if all we’re doing is detecting those annoying potholes. Good design works for all of us in the end.

